Yahoo! recently released a new Fetch Page module which dramatically increases the number of useful things that Pipes can do. With this new "pipe input" module we're no longer restricted to working with well-organised data sets in supported formats such as CSV, RSS, Atom, XML, JSON, iCal or KML. Now we can grab any HTML page we like and use the power of the Regex module to slice and dice the raw text into shape.
In a nutshell, the Fetch Page module turns Yahoo! Pipes into a fully fledged web scraping IDE!

As it happens, I already have a web scraping project which has been broken for some time now. I don't have the energy to check out the hacky old PHP scrapers and debug the problem. But with Yahoo! Pipes and the Fetch Page module to hand, I can throw away my PHP scripts and their associated libraries, delete the cron jobs and free my overloaded webserver from the onerous responsibility. Time to get cracking.
The Task at Hand
My web hosting provider (LunarPages - affiliate link alert!) runs a useful web forum at lunarforums.com. There are many different boards, the most useful being the announcement style boards such as Server Information. Unfortunately, the forum software only provides a single feed that contains the last 10 posts across all the boards on the entire site. But I want a feed of the last few posts to the boards I'm interested in, so I can keep up to date on the latest patches and hardware upgrades that might affect my sites without having to wade through posts from the "spaghetti crocheting" board.
So, what will this entail?
Looking at the first page of the Server Information board, I can get most of the information I need from here. Each row of the table shows a topic posted to the board, and will be a single item in the RSS feed. Each row provides the URL for the topic to use as the item link, the item title, the name of the author and the published date of the post.
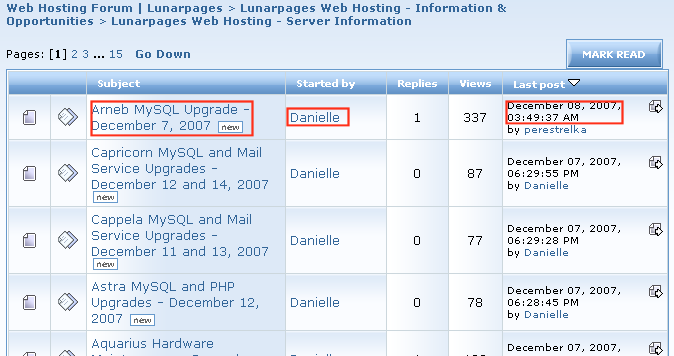
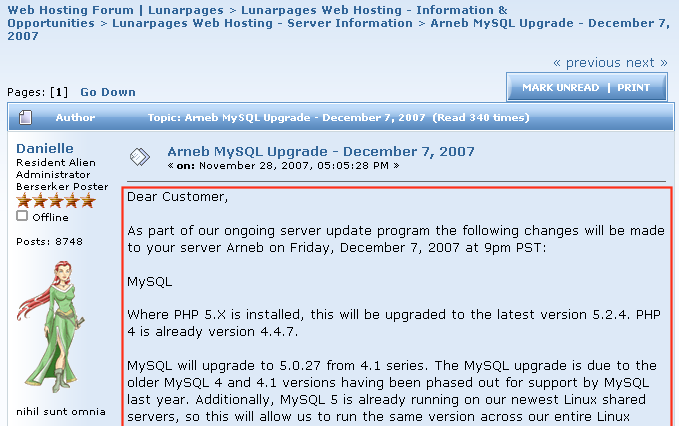
For the content of each item in the feed, I'll have to follow the link to the topic and extract the content of the first post. I'm only interested in the announcement style boards, so I don't really need entire threads of posts to a topic.
Starting the Pipe
It's time to head on over to Yahoo! Pipes, log in, and create a new pipe. If you don't want to follow along at home, you can view the source for one I made earlier at http://pipes.yahoo.com/daybarr/lunarforums. Note how Pipes lets you edit your pipe URLs now. Much better than http://pipes.yahoo.com/pipes/pipe.info?_id=sm_Vqdqk3BGGw_O5yp1_DQ
To get started, drag a Fetch Page module from the Sources section of the Library pane onto the canvas, enter the URL for the Server Information board into the URL field, refresh the pipe debugger and behold - a single item with a content field containing the source of the Server Info board.
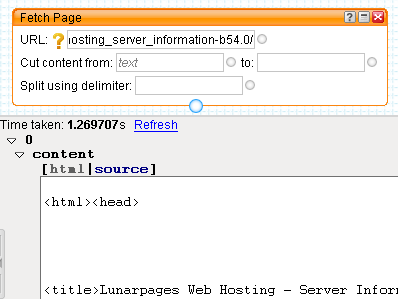
Fantastic!
We don't have to restrict the pipe to just this one board, so we can make the URL configurable by adding a URL Input module and wiring it up to the URL field of the Fetch Page module.
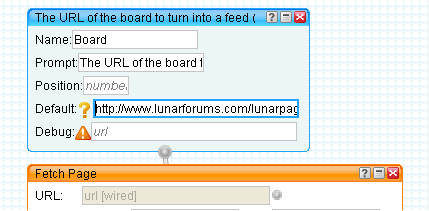
Use a Name of "Board" for the URL Input and give it a suitable Prompt. The Prompt appears next to the form field on the pipe's run page and the Name is used in the query string when running the pipe.
![]()
So we have the Fetch Page module happily returning the HTML for any board. Now we just need to take the huge string of tag soup and trim it into shape. We can use the "cut" feature of the Fetch Page module to cut out just the table that we're interested in. The "split" feature can then be used to split the table into rows, one row per post. The split will create an item in the pipe output for each row in the table that we cut out. To do their job, both "cut" and "split" require us to provide some appropriate text to use as delimiters.
To find the candidate strings for cutting and splitting, use the trusty Firebug inspector to point at the main table on the Server Information board and find the relevant part of the DOM.
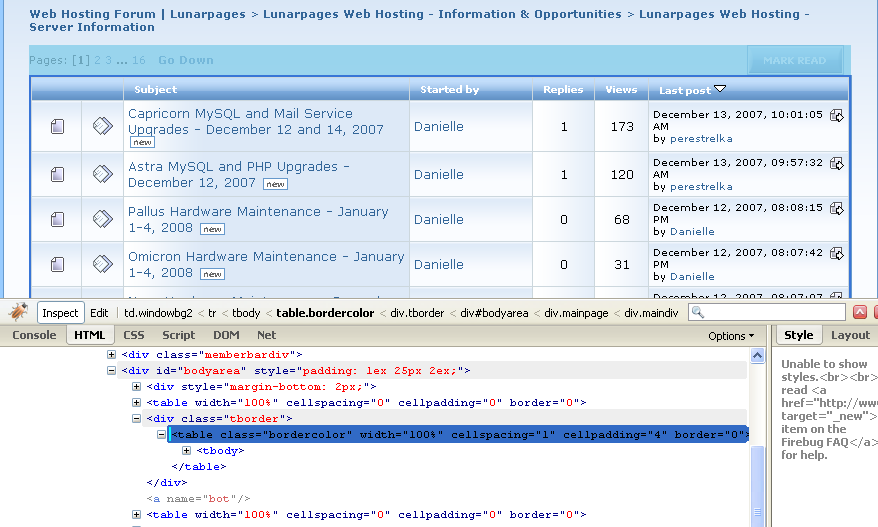
It looks like
<table width="100%" cellspacing="1" cellpadding="4" border="0" class="bordercolor">
would be a good place to cut from, and we can use </table> to stop cutting. But this doesn't seem to work
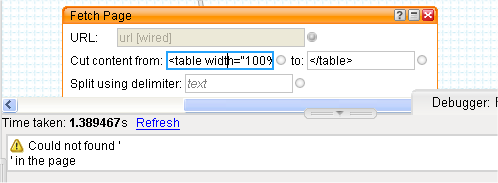
Viewing the source of the page in Firefox and searching for "bordercolor", we can find the same part of the document as it is actually written in the HTML. Aha. The attributes are shown in a different order by Firebug because it's using the abstracted DOM rather the literal page source. We can confirm the correct string to use by finding it in the Pipe Debugger too.
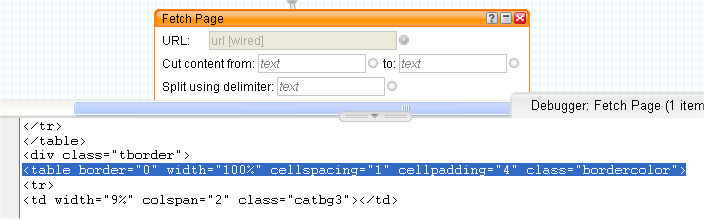
Using this string for the cut and </tr> for the split, we get 20 items in the output shown in the pipe debugger. One item for each row of the table as required.
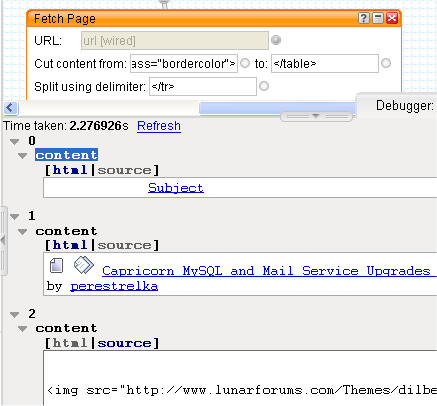
But we've also picked up the header row of the table as item 0. We don't want that, so let's remove it. Pipes has a couple of Operator modules that look promising: Truncate and Tail. Truncate will output the first 'n' items. Tail will output the last 'n' items. Given their equivalentutilities in the UNIX world, Head might be a better name for the Truncate module, but never mind.
What we need to do is output the last 'n-1' items where 'n' is the total number of items in the feed. Rather than hard code this number into the pipe (it's 19 right?), we can use the Count operator and the Simple Math module to work it out on the fly for improved robustness. A bit of cleverness with the Split module is needed, but it makes for some pleasingly bendy connectors in our pipe.
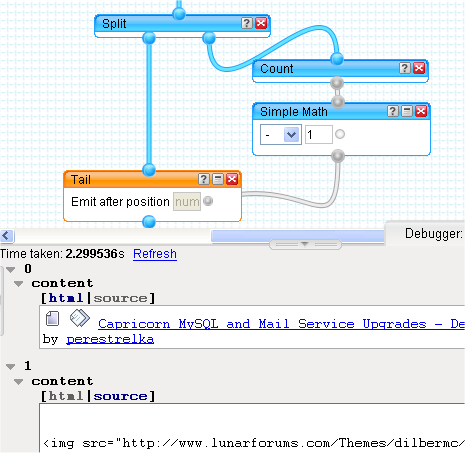
Note that the input label for the Tail module is incorrect and misleading. It should say something like "Emit last [num] items" and not "Emit after position [num]". This bug has been reported to the Pipes team so should be fixed soon.
Extracting item attributes from each table row
Before we start extracting bits from the item.content, we can make things simpler by stripping out carriage returns and linefeeds from the HTML and removing any <img> tags. This can be done with a couple of simple regexes using the (surprise) Regex module. Simply replace [\r\n] with nothing and <img src=[^>]+> with nothing, not forgetting to set the appropriate regex flags by ticking the boxes at the end of the rules.
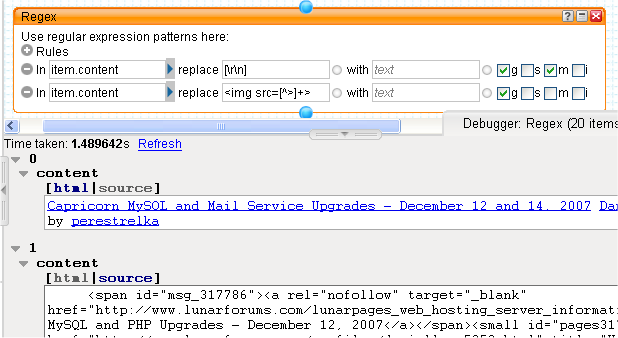
Although this step isn't strictly required, I find that doing this makes subsequent regexes and debugging simpler, which is what Yahoo! Pipes is all about.
Now we have nice clean HTML for each item representing a post to the board. We need to extract
- The title of the post
- The URL of the post
- The author
- The publishing date
These values should be in the right format and stored as appropriately named attributes of the item so that when the pipe is run and rendered as RSS, we get the correct, valid entities in the XML. The appropriate names for the attributes are (respectively)
- item.title
- item.link
- item.dc:creator (Not item.author as this must be an email address according to the RSS spec)
- item.y:published (This is a pipes-ism. The item.y:* are special attributes)
To add all these new attributes, we can use the Rename module to create them as copies of the existing item.content attribute.
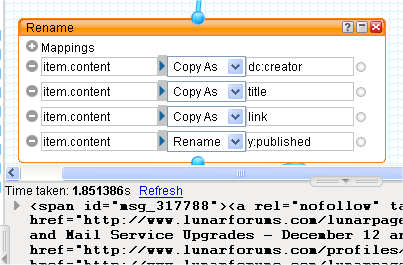
Note how the debugger now shows the item.title value instead of the item index. It's a bit unwieldy at the moment, but we're about to sort that out because the next task is to apply appropriate regexes to the HTML that currently forms each attribute, leaving only the appropriate text.
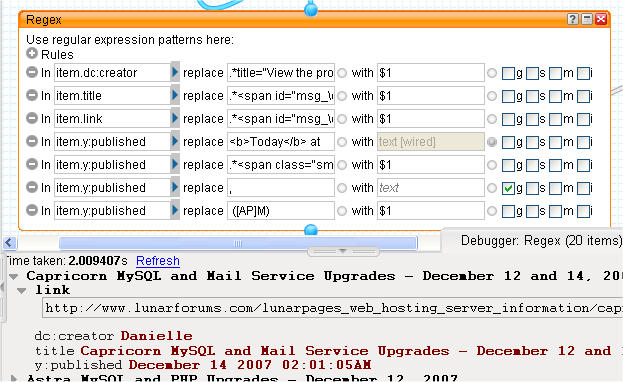
Now we have something that's starting to resemble a news feed! I won't bore you with the details of all the regexes used here (you can view the source of the published pipe to see them if you must). The interesting stuff happens with the item.y:published attribute. The extra steps are necessary because the web forum software refers to posts published today in a different format from all the other published dates.
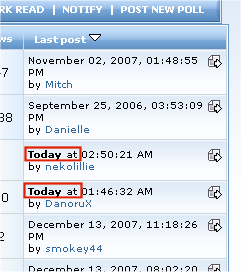
We need to substitute the literal "today" string with today's date in the same format as the other items. How do we get today's date? By using Date Builder to get the date "now", running that through the Date Formatter and hooking the resulting string up to the replacement part of the regex. Easy.
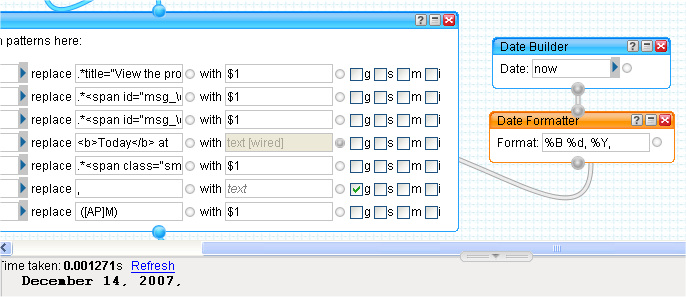
The rest of the item.y:published manipulations are to prepare the string value for the next step, turning item.y:published into the datetime value that Pipes wants instead of a string. This is easily achieved with the Date Builder module again, this time inside a Loop module which applies the nested module to every item in the input feed.
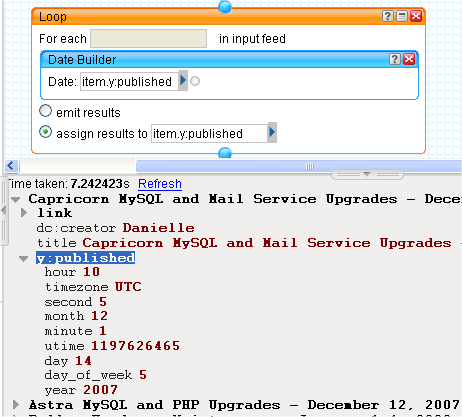
Getting the content of each post using a subPipe
So, all that's missing from our items now is the most important bit, the actual content of the post. To retrieve this we'll have to use the Fetch Page module again to get the HTML for each item.link URL. Then we'll need to use some by-now-familiar techniques to extract the content of the first post from the topic. This is done using a subPipe.
At the moment, adding a new pipe from the pipe editor itself doesn't quite work in the way we'd like, so for now, save the work so far with an appropriate name and go back to "My Pipes" to create a new one for the subPipe.
The subPipe uses the same techniques as earlier, with the URL Input module hooked up to the URL field of the Fetch Page module. The "cut" parameters for the Fetch Page module are very simple this time, and as we're only interested in the first post to the topic, there is no need for a "split" operation.
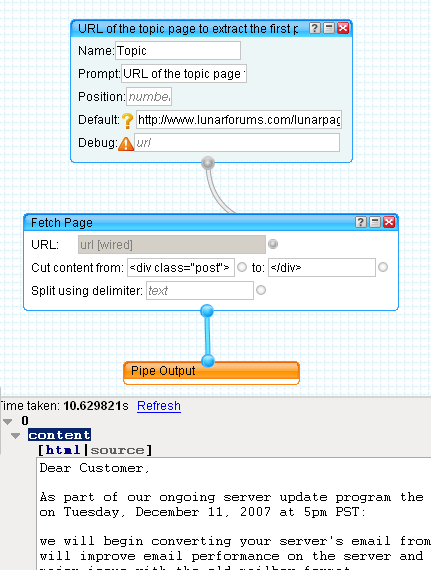
Save this new pipe with an appropriate name, and now go back to where we left off with the original pipe.
Finishing off
To run every item in the pipe through our new subPipe, simply add another Loop module and drop the subPipe inside it. The new subPipe should be under "My pipes" in the Library pane of the pipe editor. Note how the URL input for the subPipe is prompted for using the text we supplied. Hook it up to item.link to pass in the URL we extracted earlier, and then assign the first result to a new attribute, item.description
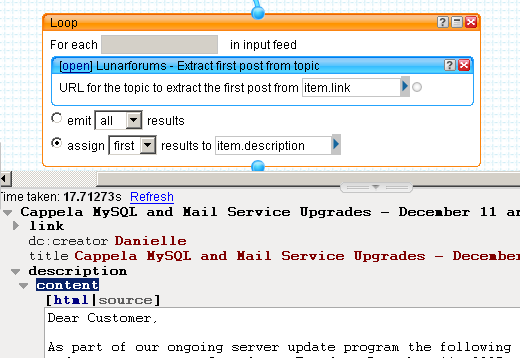
Keen observers may note that the subPipe we created for use in this Loop is so simple that we didn't actually have to create it as a separate pipe. We could simply have placed the Fetch Page module into the Loop and hooked up its URL field to the item.link directly. This is true, but it doesn't give us as much flexibility. If we ever wanted to do more work when extracting the first post from a topic, such as adding a "Created with Yahoo! Pipes!!" footer to the item content, then we can do this simply by editing the subPipe. If we didn't use a subPipe we'd have to add another Loop module to the main pipe for each additional step because each instance of the Loop module can only contain a single module.
So, we've got everything we need in our feed, but we're not quite done yet. The content of the post is stored in item.description.content but we need it in item.description. Also, it would be good to add a GUID for each post item, and for this we can just use the value of item.link (which uniquely identifies each topic) for the item.y:id.value attribute (another Pipes-ism which is used to produce GUIDs in the RSS when the pipe is run). We can use the Rename module again to accomplish both of these tasks.
All that then remains is to hook up the end of the pipeline to the Pipe Output and we're done.
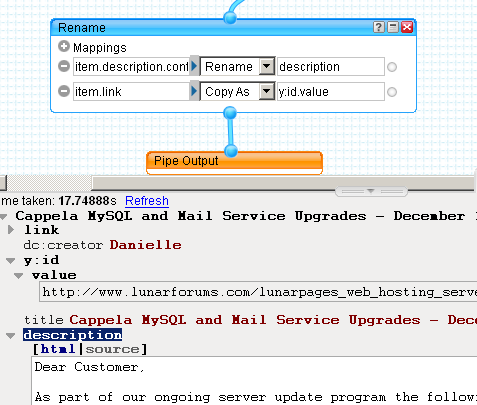
One drag and drop web scraper completed.
In use
You can view and run the published pipe at http://pipes.yahoo.com/daybarr/lunarforums. Here's the output, served up as RSS and as viewed by Google Reader.
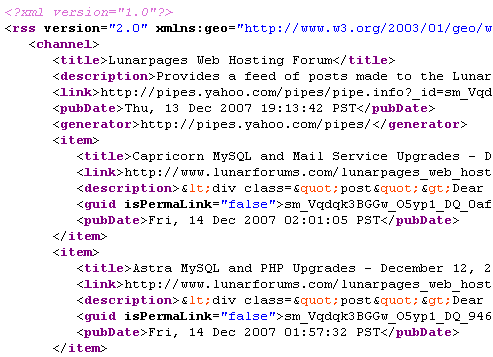
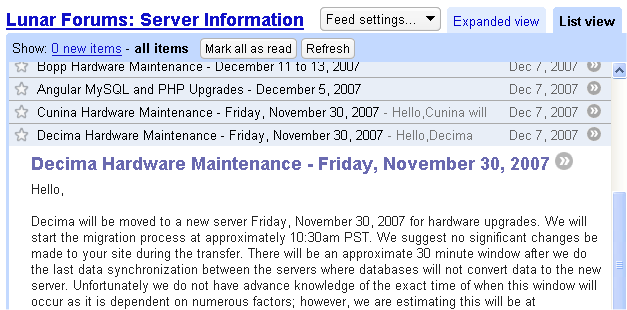
If you're a LunarPages customer, or just want to keep up to date with some of their forums, then I've pre-configured a FeedBurner feed of the pipe output for each of the major boards. You can get a list or an OPML file from this forum post.
More Pipes stuff to come
This post is the first (and probably the longest!) of a mini-series of posts on Yahoo! Pipes that I'm planning. I'm not sure when I'll have a chance to actually post these, so subscribe now if you're interested in catching them.
Credits: The original nutshell image is published on flickr and licensed under a Creative Commons license by twinsparc. "Pipes in a nutshell" modifications by me.
24 comments
Interesting. I also have an out-of-date web scraping project (putting locations from primelocation.com onto a Google map). My approach was to pipe the html through tidy, then process as XHTML. I'm going to try Yahoo pipes instead.
If you use bordercolor to find the part you want, then what will happen if the forum has style template options.
Would that not pose a problem?
/Nick
This shouldn't be a problem because the Yahoo! Pipes robot that visits the forum website is always served the default template. The robot won't ever choose a different forum style, if you like. Of course, if the owner of the forum being scraped were ever to change the default template in any way, then the scraper may well break, although this doesn't happen very often in practice.
This kind of page scraping is also easily achieved -- perhaps more easily achieved -- using Dapper (www.dapper.net).
Using Dapper you can transform the scraped content into HTML, XML, Email, and many other formats with just a few mouse clicks. Best of all, you could even use a Yahoo! Pipe to cosume the Dapper output and perform additional processing if you wish.
Tony Loton, author -- "Mashups Made Easy with Dapper" "Working with Yahoo! Pipes, No Programming Required" "Mashup Case Studies with Yahoo! Pipes" http://www.lotontech.com/it_books.htm
That was helpful, thanks!
If wont read a web page for extract the information, i use your tutorial but i have more problem. can you help me? the page is http://www.gazzetta.it/Ciclismo/Primo_Piano/2009/01/16/priamo_1601.shtml
i need only this text:
title: Caso Sella, la Procura chiede 4 anni per Priamo
descrption: Il veneto verrà giudicato dal Tribunale nazionale antidoping per violazione dell'art. 2.8 del codice Wada. E' accusato di essere coinvolto nel caso Sella Matteo Priamo, 26 anni, professionista dal 2006. Bettini Matteo Priamo, 26 anni, professionista dal 2006. Bettini ROMA, 16 gennaio 2009 - Quattro anni di squalifica. Ecco la richiesta della Procura antidoping del Coni a carico di Matteo Priamo, 26 anni, il corridore veneto della Csf Group-Navigare che dovrà rispondere della violazione dell'art. 2.8 del codice WADA. L'accusa è quella è quella di "aver fornito assistenza e aiuto o comunque assicurato complicità in riferimento ad una violazione o tentata violazione nell'ambito del procedimento disciplinare del ciclista Emanuele Sella". Priamo, che all'ultimo Giro d'Italia ha vinto la tappa di Peschici e ha colto due successi al Giro di Turchia, era stato tirato in ballo proprio dal compagno di squadra, positivo all'Epo di terza generazione durante un controllo a sorpresa. Il 1° dicembre Sella è stato squalificato dal Tribunale nazionale antidoping per un anno, beneficiando di uno "sconto" di pena in relazione alla sua collaborazione.
regards Max
@ Max: I had a quick go at this, and got something like you want here
http://pipes.yahoo.com/daybarr/gazzetta
You should be able to copy this pipe and adjust it a little to get exactly what you need.
Good luck, Day
Hello, I'm new on yahoo pipes. My first test worked pretty good. But now I encountered a problem. I'm doing my filters and stuff always on the same sources (rss feeds), therefore I created several subpipes so I only need to drag these subpipes instead of integrating everytime the same sources. But it doesn't work! The results I get are not the same (nearly no result). Is something wrong with my pipe or is it a dysfunction of yahoo pipes?
(See me pipe: with my feeds one by one (fetch feed) and with my subpipes) : http://pipes.yahoo.com/pipes/pipe.info?_id=GpunftTy3RGjywG8pgt1Yg )
Thanks for your help,
Christine
@Christine, I'd not encountered this problem before, but I see what you mean.
At the moment, I get 9 results when I hook up the two Fetch Feed modules instead of the Subpipe modules, and only 1 result with the Subpipe modules. It looks like the Subpipe modules are outputting the same results as the Fetch Feed modules, but in a different order (use a Sort module and sort by title to see that the top few lines match).
Perhaps the extra processing involved in loading 2 Subpipes is causing the backend to timeout when halfway through the list, resulting in only some of the items being filtered and the rest being dropped? I'm just guessing though.
By the way, I notice that you Split before the two Filter modules and then Union together again. But you could simplify the pipe by combining the two Filter modules into one module with all the Rules, and removing the Split and Union. I don't think it will solve your problem but might make your pipe easier to edit?
/Day
Hi Day, Thank you for your tutorial. I am new at Yahoo Pipes and have followed your tutorial to extract feed from this website, it's in Indonesian:
http://www.lantas.metro.polri.go.id/news/index.php?id=0
The website is about traffic information in Jakarta, Indonesia.
This is what I have so far, but it seems that pipes could not distinguish the attribute we want to extract from the content i.e. title, description, date/time and link (Step 11).
http://pipes.yahoo.com/pipes/pipe.info?_id=9MlGVSb_3RGrgkFN37Vd_w
And also for everytime we replace with $1, the number 1 appears in the content. What am I doing wrong?
Thank you so much for your reply.
@Abigail
From what I can see, you aren't doing anything wrong, you just haven't quite finished and are stuck at the Regex module, which can be tricky to use. There are some tips on how to use Regexes with Yahoo! Pipes here.
This may be because you are not using a capturing group in your regex. Anything inside round brackets is captured and then available in one of the $1 $2 $3 variables, in the order in which the groups appear in your pattern.
I have made a copy of your Pipe and added some working regexes at http://pipes.yahoo.com/daybarr/tmc02. I hope that does what you want. My Indonesian is not too good. :)
Thank you so much! It is exactly what I wanted. Yes! I have had trouble with the Regex module. Now I just need to add your last few steps to add the full content :)
I will be publishing this feed on my website, however there is no source to each entry. Is it possible, by using the pipes, to automatically add Text input of the feed source (after each title or after each entry?) "Source: TMC Polda Metro Jaya"
Sorry if I am taking too much of your time. Thank you again.
Hi I'm new to utilizing the Yahoo! pipes concept as well. I'm on a learning curve and wanting to know how this link scraping technique could work in a meta search engine environment as I've been trying to find scripts and ideas about this.
Pipes is totally new to me. I am trying to harvest tweets containing key words and reposting them. My Pipe is working fine but I wanted to change the output before I retweet it. I am useless with regular expressions.
I need for regex to modify the item.author.name from its full size to just the handle. for example from Swineheart (Scott Fahrenkrug) to just Swineheart. Can you tell me a generic regular expression for doing this to all item.author.names?
Hi Scott,
This is totally untested off the top of my head, but I think you need something like this
In
item.author.namereplace^([^\(]*)\s*\(.*\)$with$1Note the regular expression breaks down as follows
^- Match at the start of the string(- Start Capture Group 1[^\(]*-Zero or more*characters that are NOT^a literal bracket\()- End Capture Group 1\s*- Zero or more whitespace characters\(- Literal open bracket.*- Zero or more characters\)- Literal close bracket$- End of stringYou may well need to fiddle a bit, as I say I haven't tested this!
Good luck,
Day
This ALMOST works, maybe you can help me perfect it? My tube is like this:
Fetch Feed (from a twitter search)-----Filter (to not find my posts or Retweets)-----String Builder inside a Loop---Regex---Pipe output
I need to grab both the item.author.name and the item.title in the String Builder/Loop and assign these to item.title I thought I would then do the cleanup of item.title in Regex.
However, the only way I got your reg expression to deliver the desired truncated author name was when; the item.title is removed from the String Builder/Loop.
When I add it back in I get the full author.name back???
Any suggestions? Scott
The regex I gave you was for working on the item.author.name as you described it, not some combination of the item.author.name and item.title together.
Try moving the Regex module before the String Builder?
This worked! I tried it once and didn't get results, but this time it delivered! THANKS!!
Excellent guide! I just used it to create a "Latest Google Chrome Extensions" feed in Yahoo Pipes by scraping the Chrome extensions site (http://pipes.yahoo.com/pipes/pipe.run?_id=3a278cf4a09002559eabe05741ff596d&_render=rss).
Thank you.
Artem
http://beerpla.net
http://twitter.com/ArtemR
Thanx for your quality guide!
Thanks a lot for the article. I have been doing extraction jobs with Outwit Hub for a while now. It seems quite a bit simpler. But pipes may come very handy in some cases. Is it being followed and updated by Yahoo?
You seems really good at yahoo pipes. This tutorial is the greatest I've ever seen about the subject. I would like to ask a question that maybe stupid for you :
Do you know how to agregate rss posts from feeds in one post ? I would like to have my daily post on a subject and not as many posts as there are in my feeds.
Thank you.
Really great guide!
I have a few questions though,
I have followed yours exactly, and it works perfectly. I then modified mine slightly, for example i want the time of last post to be directly copied, rather than creating. I would also like the posters name to be displayed under the time of post.
I see you fetch who the poster is, but never use it?
Here is my pipe
Help is much appreciated!
Hi Day, Will you help me with my problem?
I've created a pipes to fetch a site's rss feed. I want it to skip the first 5 items and start fetching from the 6th. What module/s to add? and how
Any help would be greatly appreciated. Thanks a lot.
Gene
Leave a comment